What Agentic AI Is Not
The term agentic AI has rapidly entered mainstream technical discourse, but its meaning has been diluted by conflation with retrieval-augmented generation (RAG) pipelines, chatbots with session memory, and LLM wrappers with tool access. These are useful systems, but they are not agents.
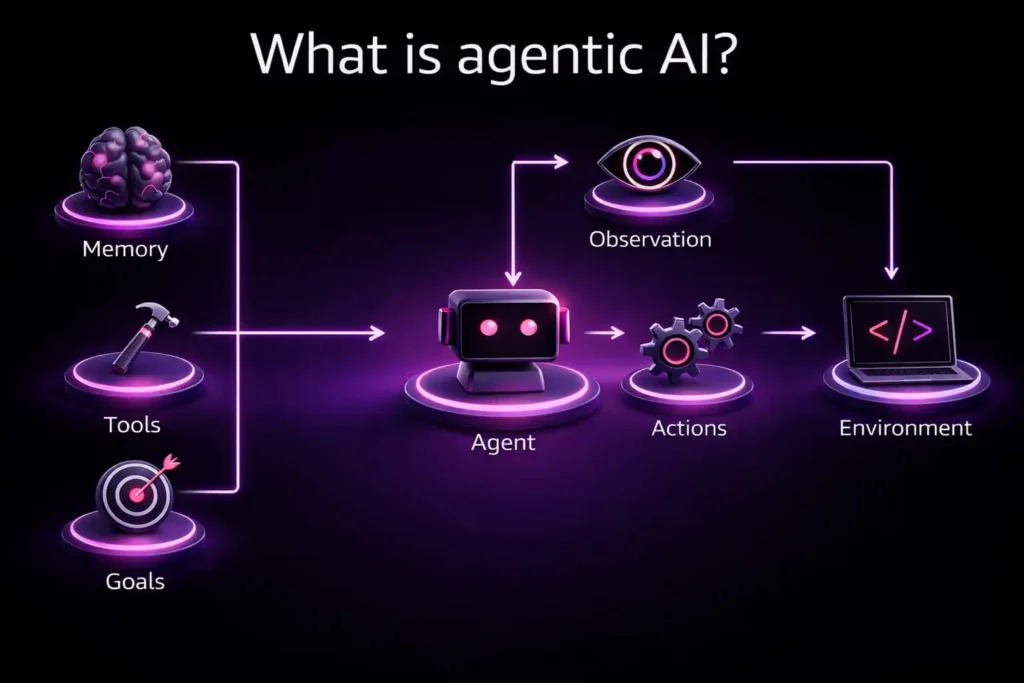
An agentic AI system is a closed-loop autonomous system that continuously perceives its environment, reasons over its goals, selects and executes actions, and updates its internal state based on observed outcomes. The operative word is loop. Unlike request-response architectures, an agent does not terminate after a single inference step. It persists, adapts, and acts with intentionality shaped by accumulated context.
Anatomy of the Agentic Control Loop
The canonical agent loop can be formalized as a cycle across five interdependent stages, each mediated by persistent memory and tool interfaces:
Goals → Observation → Reasoning → Action → Environment
Memory and tools operate as cross-cutting concerns that shape every transition in the loop. Below is a decomposition of each component:
Goals
Goals define the agent’s intent and serve as the optimization target for all downstream reasoning. In production systems, goals are typically hierarchical: high-level objectives decompose into subgoals, which in turn generate discrete task plans. Critically, goals in an agentic system are not prompts. A prompt is a stateless input to a model; a goal is a persistent directive that survives across multiple reasoning cycles and can be revised as the environment changes.
Memory
Memory provides the agent with context that extends beyond the current interaction. This includes short-term working memory (recent observations and intermediate results), long-term episodic memory (historical interactions and outcomes), and semantic memory (learned facts and domain knowledge). Without memory, the agent has no continuity—each cycle becomes stateless, and the system degenerates into a standard inference pipeline.
Tools
Tools are the agent’s interface to the external world. They allow the system to act, not merely respond. This includes API calls, code execution, database queries, file system operations, and interactions with external services. The selection and orchestration of tools is itself a reasoning problem—one that differentiates robust agentic systems from brittle single-tool pipelines.
Observation
Observations update the agent’s internal state based on real outcomes from the environment. This is the feedback channel that closes the loop. An agent that cannot observe the results of its actions cannot adapt, correct errors, or verify task completion. Observation quality—including latency, fidelity, and noise characteristics—directly determines the system’s reliability under real-world conditions.
Actions
Actions are the agent’s mechanism for changing the environment intentionally. In a well-designed system, actions are bounded by policy constraints, validated against expected outcomes, and logged for auditability. The critical distinction from conventional LLM outputs is that actions have side effects—they modify external state in ways that are observable and consequential.
Why Most “Agents” Fail at Scale
The model is only one component inside the agentic loop. What determines whether an agent works in production is the infrastructure surrounding the model. The following system-level concerns are what separate prototype agents from production-grade autonomous systems:
- Task Orchestration: How are multi-step tasks decomposed, scheduled, and coordinated? Without a robust orchestration layer, agents cannot handle concurrent subgoals, manage dependencies, or recover from partial failures.
- Decision Constraints: How are the agent’s decisions bounded? Unconstrained reasoning produces unpredictable behavior. Production agents require guardrails—policy layers, permission models, and scope limitations—that restrict the action space to safe and intended operations.
- Failure Detection and Recovery: How does the system detect when an action fails or produces an unexpected outcome? Agents without exception handling, retry logic, and fallback strategies degrade silently—a failure mode far more dangerous than a hard crash.
- Auditability and Explainability: How are actions logged, traced, and explained? In regulated environments, this is non-negotiable. Even in unregulated contexts, the inability to explain agent behavior erodes trust and makes debugging intractable at scale.
Without this infrastructure, the agentic loop collapses into probabilistic guesswork. The system may produce correct outputs intermittently, but it cannot reliably achieve its goals under the variance and adversarial conditions present in real-world environments.
The Core Design Principle
Autonomy does not emerge from smarter model outputs. It emerges from well-designed control loops.
This is the central insight that separates agentic AI engineering from prompt engineering. Improving the reasoning step in isolation—through better models, longer contexts, or more sophisticated prompting strategies—yields diminishing returns when the surrounding system lacks the structure to translate reasoning into reliable, verifiable action.
The most effective agentic systems in production today share a common architecture: they invest disproportionately in the orchestration, constraint, observation, and recovery layers—not in the model itself. The model is a component. The system is the product.
Key Understanding
Agentic AI represents a fundamental architectural shift from stateless inference to persistent, goal-directed autonomous systems. The distinction is not semantic—it is structural. Building agents that work in production requires treating the model as one component within a larger closed-loop system, and engineering the surrounding infrastructure with the same rigor applied to any mission-critical distributed system.
The field will advance not by building smarter models, but by building better systems around them.