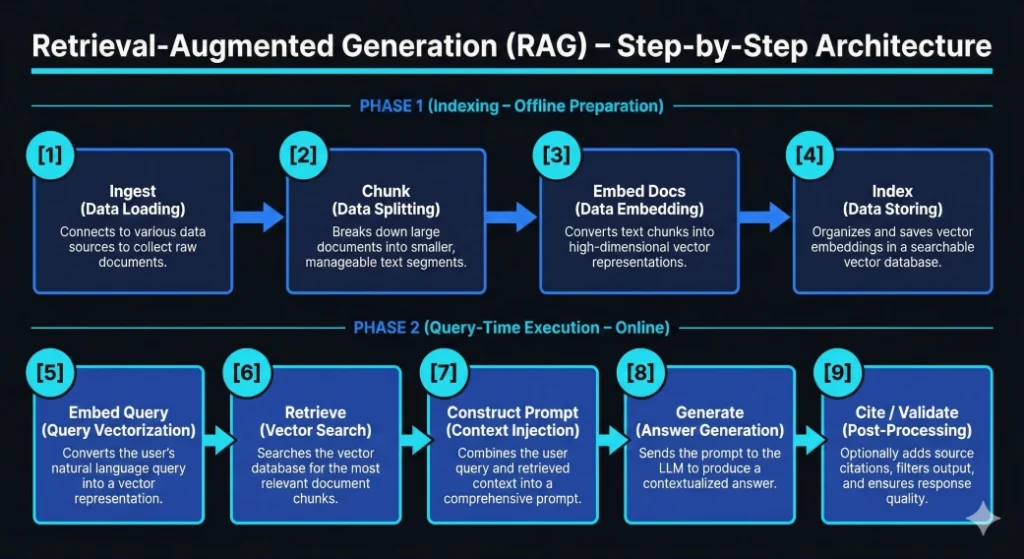
RAG gets thrown around a lot — in pitch decks, job postings, LinkedIn hot takes. But when you strip away the hype, what’s actually happening under the hood?
RAG is a two-phase system:
- Phase 1 — Indexing (Offline Preparation)
- Phase 2 — Query-Time Retrieval + Grounded Generation (Online Execution)
No magic. No sentience. Just structured information flow.
Let me walk you through all nine steps — the way I’d explain it to an engineer on day one of building one.
Phase 1: Indexing (Offline Preparation)
These steps happen before a user ever asks a question. Think of this as building the library before anyone walks through the door.
[1] Ingest — Data Loading
Every RAG system starts here. You connect to your data sources — document stores, databases, APIs, file systems — and extract raw text along with any useful metadata (timestamps, authors, document types).
Nothing fancy yet. You’re just collecting the material.
[2] Chunk — Data Splitting
Raw documents are too large to search effectively. So you break them into smaller, bounded segments — chunks. These might be paragraphs, fixed token windows, or semantically coherent sections.
This step matters more than most people realize. Good chunking directly impacts retrieval quality. Chunk too large and you dilute relevance. Too small and you lose context. This is where a lot of RAG systems silently fail.
[3] Embed Docs — Data Embedding
Each chunk gets converted into a high-dimensional vector using an embedding model. This is the bridge between human-readable text and machine-searchable space. The vector captures the meaning of the chunk, not just its keywords.
[4] Index — Data Storing
Those vectors (along with their metadata) get stored in a vector database or hybrid search index — tools like Pinecone, Weaviate, Qdrant, or pgvector.
At this point, your knowledge base is searchable in semantic space. Phase 1 is complete. The library is built, organized, and ready for visitors.
Phase 2: Query-Time Execution (Online)
Now a user shows up and asks a question. These steps run on every request, in real time.
[5] Embed Query — Query Vectorization
The user’s natural language query gets converted into a vector using the same embedding model from Phase 1. This ensures the query lives in the same mathematical space as the indexed documents — apples to apples.
[6] Retrieve — Vector Search
The system runs a similarity search (typically top-K nearest neighbors) against the vector database. The result: the most semantically relevant chunks from your knowledge base, ranked by closeness to the query.
This is the “Retrieval” in Retrieval-Augmented Generation. No retrieval, no grounding. Just vibes.
[7] Construct Prompt — Context Injection
Here’s where it all comes together. The retrieved chunks get injected into the LLM prompt alongside the original user query. You’re essentially telling the model: “Here’s what you know. Answer based on this.”
Prompt construction is an engineering problem — how you format context, set boundaries, and instruct the model all affect output quality.
[8] Generate — Answer Generation
The LLM produces a response using the provided context. It’s not pulling from some mysterious internal memory. It’s reading what you gave it and generating an answer grounded in your data.
This is the “Generation” in RAG — but it’s augmented generation because the model’s output is anchored to retrieved evidence, not left to hallucinate freely.
[9] Cite / Validate — Post-Processing
The final step is often overlooked but critical in production systems. You attach source citations, enforce output schemas, apply content filters, or run guardrails. This is where you build trust and ensure response quality before anything reaches the end user.
The Minimal Mental Model
If all nine steps feel like a lot, here’s the distilled version:
Index → Retrieve → Ground → Generate
That’s RAG.
It’s not about making the model “smarter.” It’s about giving it the right context at the right time and constraining generation to what’s actually supported by your data.
Why This Matters
Engineers who understand this architecture stop building hallucination machines — and start building systems.
Systems that can be debugged. Systems where you can trace why the model said what it said. Systems where retrieval quality, chunking strategy, and prompt design are all levers you can tune independently.
And systems scale