Generative AI doesn’t “think” the way humans do. There’s no inner monologue, no sudden flash of inspiration, and definitely no existential crisis about word choice.
What it does do is perform a very specific mathematical sequence — over and over again — to predict the next token. That’s it. One token at a time. And somehow, from that deceptively simple loop, you get essays, code, poetry, and the occasional hallucinated fact.
Let me break down exactly what happens when you type something like “AI is” into a generative model.
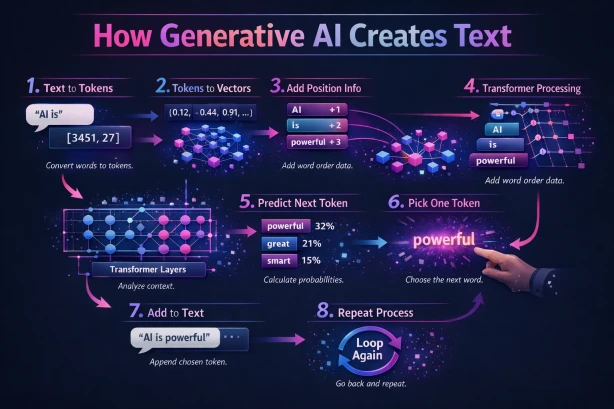
Step 1: Text to Tokens
Before the model can do anything, it needs to convert your words into numbers. Human language means nothing to a neural network — math is the only language it speaks.
So “AI is” gets split into tokens — discrete chunks that the model has learned to recognize. In this case, something like [3451, 27]. These aren’t arbitrary; they come from a pre-built vocabulary the model was trained with. Some tokens represent whole words, others represent fragments or subwords. The word “powerful” might be one token. The word “unbelievable” might be three.
Step 2: Tokens to Vectors (Embeddings)
Each token ID now gets mapped to a high-dimensional vector — a long list of numbers like (0.12, -0.44, 0.91, ...) that captures the meaning of that token. Think of it as the model’s internal representation of what a word means, not as a dictionary definition, but as a position in a vast semantic space.
Words that are similar in meaning end up close together in this space. “King” and “queen” are neighbors. “Toaster” is way off somewhere else.
Step 3: Add Position Info
Here’s a subtle but critical step. Transformers process all tokens simultaneously — they don’t read left to right like you do. So the model needs to be told where each word sits in the sequence.
Positional encodings get injected into each embedding. Now “AI” knows it’s word 1, “is” knows it’s word 2. Without this, the model would treat “the dog bit the man” and “the man bit the dog” as identical inputs. Word order matters.
Step 4: Transformer Processing
This is where the magic — or more accurately, the linear algebra — happens.
The enriched embeddings pass through multiple transformer layers, each containing a mechanism called self-attention. Self-attention lets every token look at every other token in the sequence and ask: “How relevant are you to my meaning right now?”
When processing the word “is” in “AI is,” the model attends to “AI” to understand the subject. Across dozens of layers, the model builds increasingly sophisticated representations of context, grammar, intent, and even tone. By the time tokens emerge from the final layer, they carry a deep contextual understanding of the entire input.
Step 5: Predict Next Token
Now the model produces its output: a probability distribution over its entire vocabulary. Every possible next token gets a score.
For “AI is,” the output might look something like:
- powerful → 32%
- great → 21%
- smart → 15%
- the → 8%
- …and thousands more trailing off toward zero
The model isn’t picking a word yet — it’s telling you how likely every word is as the next token, given the context.
Step 6: Pick One Token
Time to make a choice. The model samples from that probability distribution. This is where temperature and other sampling parameters come into play.
- Low temperature → The model plays it safe, almost always picking the highest probability token. Predictable, coherent, but sometimes boring.
- High temperature → The model gets adventurous, giving lower-probability tokens a real shot. More creative, but potentially chaotic.
In our example, the model selects: “powerful.”
Step 7: Add to Text
The chosen token gets appended to the sequence. What started as “AI is” is now “AI is powerful.”
Simple as that. No drama. Just concatenation.
Step 8: Repeat
Now the entire process starts over. The model takes “AI is powerful” as its new input and runs the full pipeline again — tokenize, embed, position, attend, predict, sample, append.
And again. And again. Until it hits a stop condition (a special end-of-sequence token, a length limit, or your patience).
The Big Picture
At its mathematical core, every generative AI model is computing a single function:
P(next token | all previous tokens)
That’s the whole game. Text goes in, numbers come out, context gets analyzed, probabilities get calculated, a token gets sampled, and we loop.
Text → Numbers → Context → Probabilities → Sampling → Repeat.
Simple loop. Powerful emergent behavior.
What makes this remarkable isn’t any single step — it’s that billions of parameters, trained on massive datasets, can turn this token-by-token prediction into coherent paragraphs, logical arguments, and working code. The intelligence isn’t in the loop. It’s in the weights.