A Research Assistant That Can't Make Things Up
An AI-powered writing assistant for PhD students and researchers that answers APA 7 formatting and citation questions — but only using evidence from your actual sources, with page numbers and quotes you can verify.
ROLE
AI Engineer
TYPE
RAG System with Guardrails
STACK
Next.js · TypeScript · OpenAI · HuggingFace · pgvector · Docker
CODE

THE PROBLEM
Writing a dissertation means citing everything perfectly — and AI chatbots can't help with that
PhD students and researchers spend enormous time formatting citations, cross-referencing sources, and making sure every claim in their writing is backed by real evidence. APA 7 is the standard, and getting it wrong can mean revisions, credibility issues, or worse.
General AI chatbots are useless here — they hallucinate citations, invent page numbers, and confidently quote sources that don’t exist. For academic writing, that’s not just unhelpful. It’s dangerous.
APA 7th Edition is Complex
Hundreds of formatting rules for in-text citations, reference lists, headings, and source types — easy to get wrong, tedious to get right.
AI Hallucinations
Standard chatbots invent citations, fabricate page numbers, and produce confident answers with zero evidence. Researchers can’t trust them.
Source Overload
Dissertations involve dozens of PDFs. Finding the right quote, on the right page, from the right source is a constant time sink.
THE SOLUTION
An APA assistant that only answers from your actual sources — or says "I don't know"
I built APA AI Atlas as a citation-first research assistant. You upload your PDFs (in our case the complete APA 7th Edition Manual), ask questions about APA formatting or your source material, and the system answers using only the evidence it can find — with page numbers, source snippets, and quotes you can verify. If the evidence isn’t strong enough, it refuses to answer rather than guess.
I originally built it to support my own doctoral work, then engineered it into a reliable tool others can use with confidence.
01
Grounded Answers
Every response is generated from your actual uploaded sources — not from the AI’s general knowledge. If it’s not in your documents, it’s not in the answer.
02
Source Citations with Page Numbers
Each answer includes numbered source references with the exact excerpt and page location, so you can verify every claim in seconds.
03
Smart Refusal
When the evidence is weak or insufficient, the system says so — instead of making something up. Silence is better than a fabricated citation.
04
Evidence Panel
A dedicated side panel shows all the source excerpts and citation context used to generate each response — full transparency, always visible.
HOW IT WORKS
Ask a question, get an answer you can trust
Behind the scenes, each question goes through a five-step pipeline: the system converts your question into a search, finds the most relevant passages in your uploaded sources, ranks them for quality, generates an answer, then validates that every claim is actually supported before showing it to you.
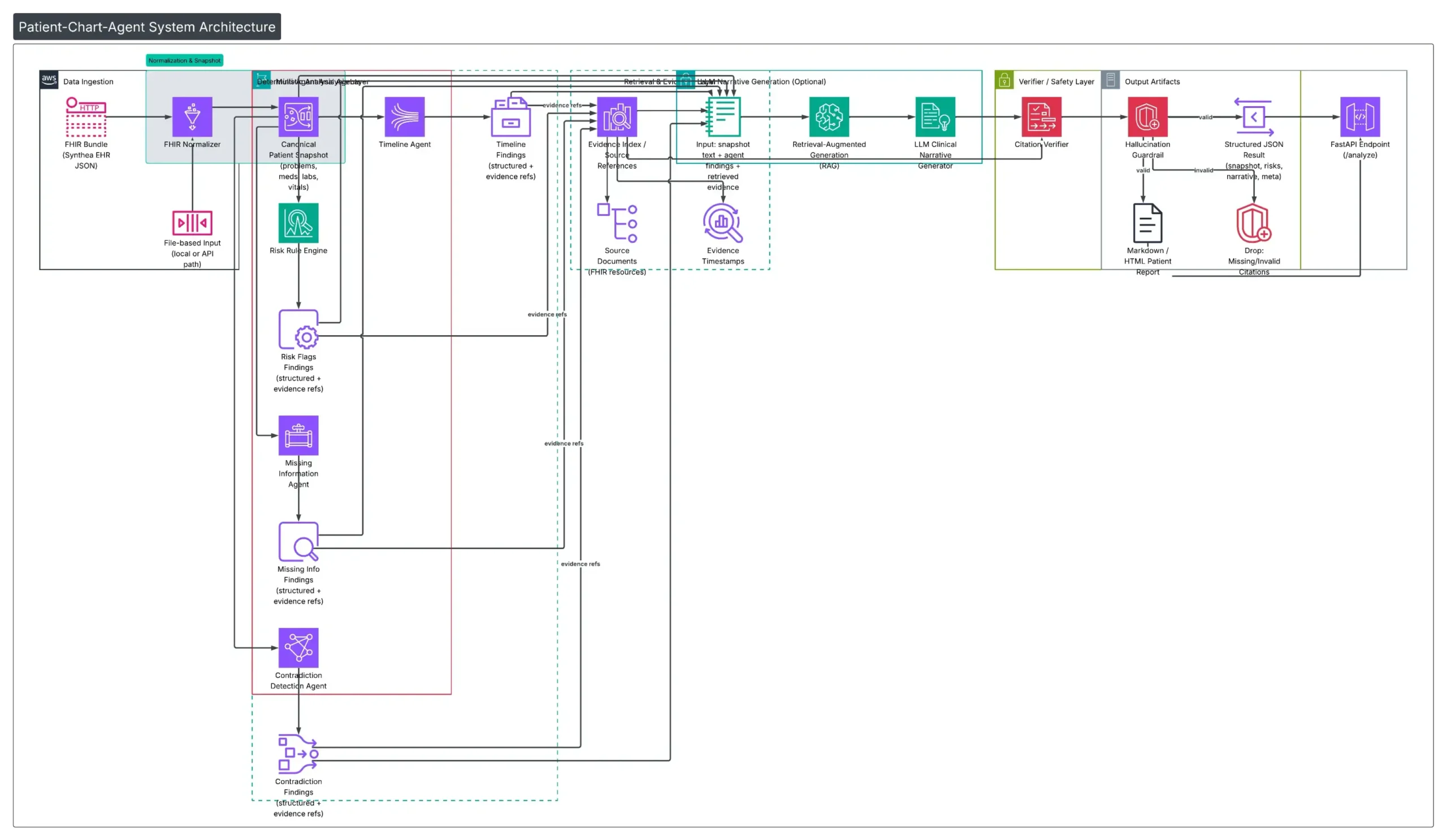
SEE IT IN ACTION
A polished interface designed for research workflows
The app features a three-panel layout: saved chat history on the left, the main conversation in the center, and a dedicated evidence panel on the right showing the exact source excerpts behind each answer.
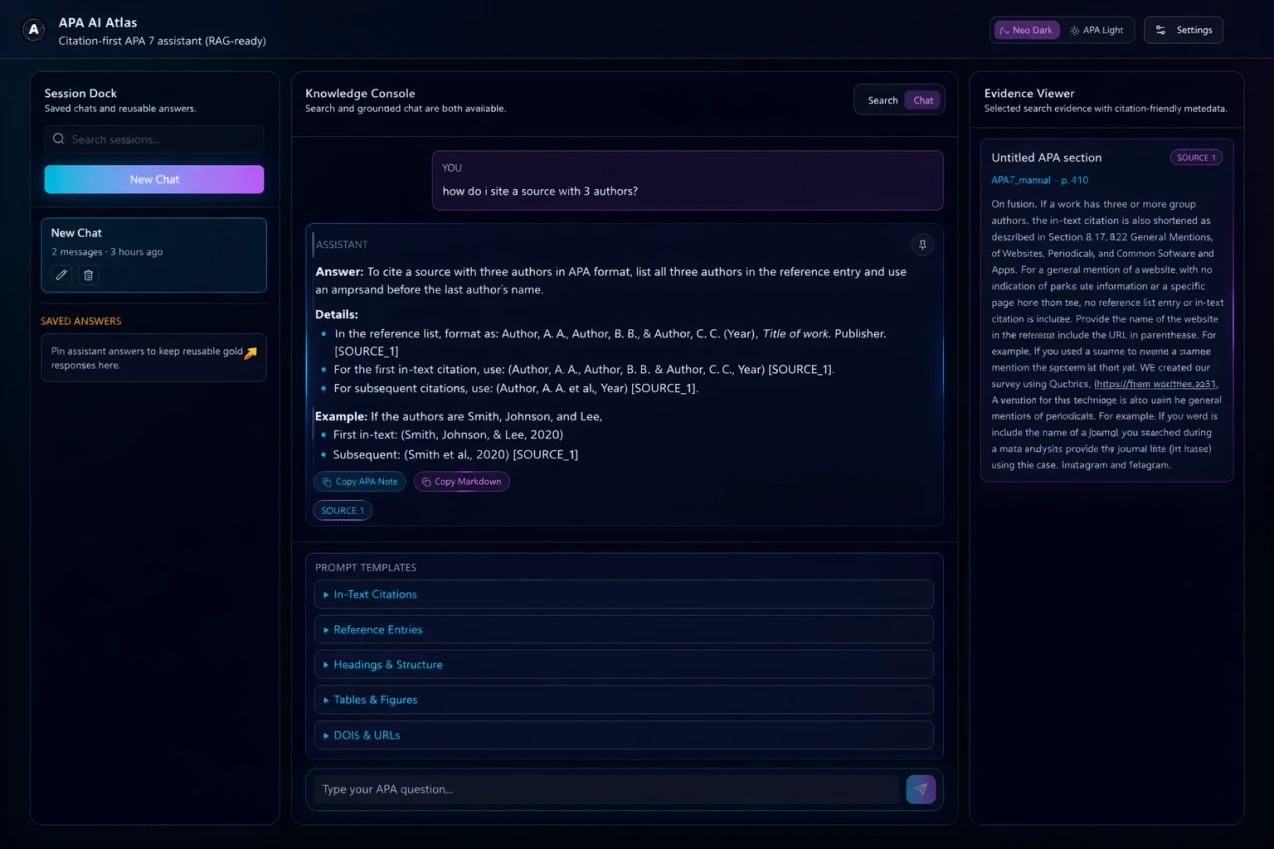
Main Chat Interface
Three-panel layout with chat history, AI conversation with grounded answers, and an evidence sidebar showing source excerpts with page references.
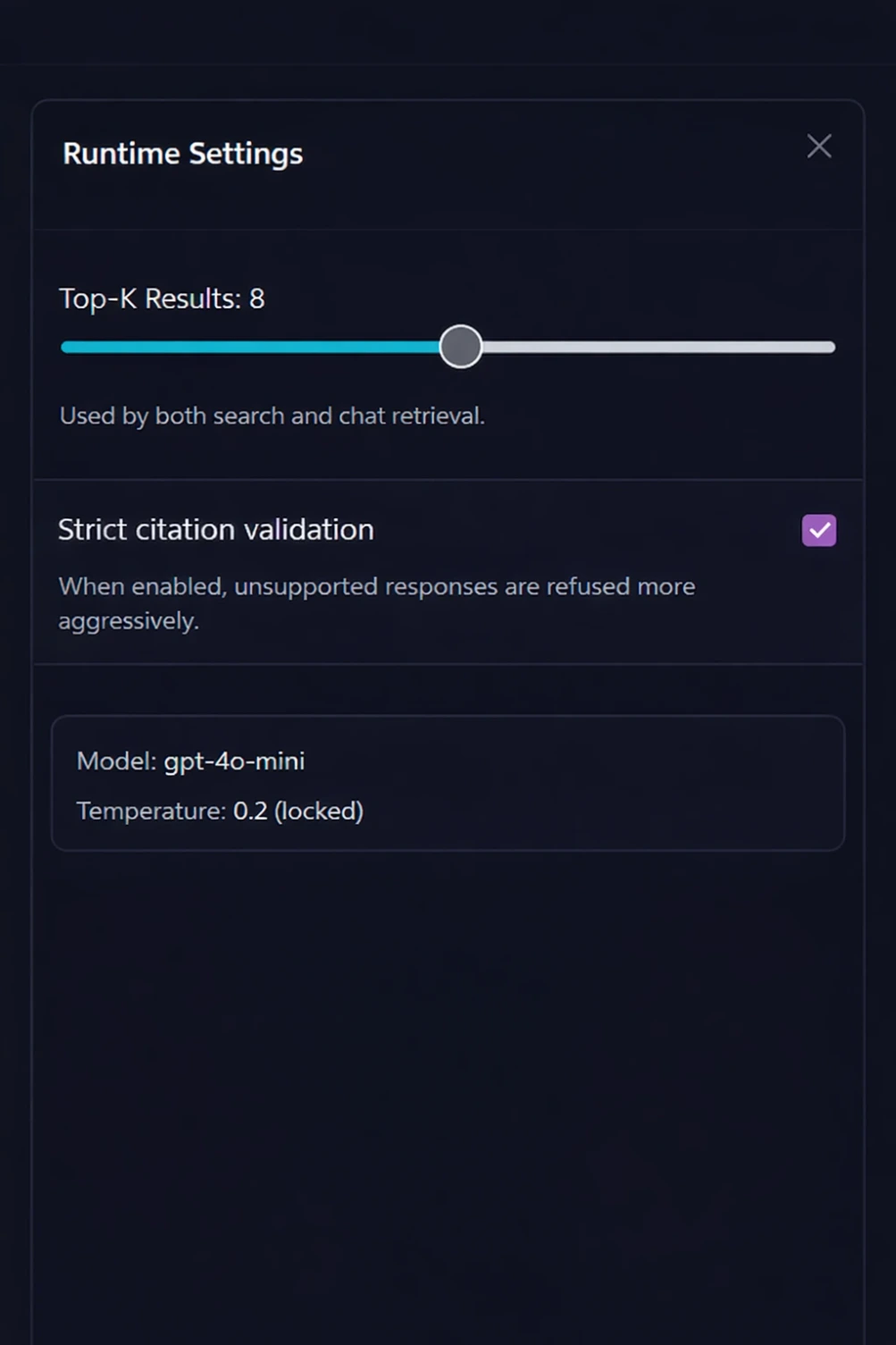
Runtime Settings
Users can control retrieval depth (how many sources to search), toggle strict citation validation, and view model parameters — giving researchers control over the system’s behavior.
ENGINEERING DECISIONS
Why I built it this way
Citation-first, not answer-first
Most AI assistants generate an answer then try to find citations to support it. This system flips that — it finds the evidence first, then generates an answer constrained to only what the evidence supports. This eliminates hallucinated citations at the architecture level.
Refusal over fabrication
If the system can't find strong enough evidence, it says "I don't have sufficient evidence to answer this" instead of guessing. For academic writing, a wrong citation is worse than no citation.
Neural reranking after vector search
Vector search alone often retrieves "close enough" results. Adding a second-pass reranking model significantly improves the quality of the evidence that reaches the AI — better evidence in means better answers out.
Evaluation built in from day one
The evaluation suite isn't an afterthought — it's part of the development loop. A golden test set catches regressions automatically, so improvements to one part of the system don't break another.
BY THE NUMBERS
Impact at a glance
100%
Per-claim citation coverage — nothing is unsourced
100%
Refusal correctness — never guesses when it shouldn’t
5
Stage validation pipeline with automated regression gating
TECH STACK
Built with
REFLECTIONS
What I learned building this
Building for yourself reveals what users actually need
I built this for my own doctoral work before engineering it for others. That meant every feature existed because I personally felt the pain — not because it seemed like a good idea in theory.
Retrieval quality matters more than generation quality
The biggest gains came not from better prompts to the AI, but from improving how the system finds and ranks evidence. Better evidence in always means better answers out.
Guardrails are a feature, not a limitation
Researchers don’t want a chatbot that always has an answer. They want one that’s honest about uncertainty. The refusal behavior turned out to be the feature users trust most.
Evaluation suites pay for themselves immediately
The golden test set caught multiple regressions during development. Without it, I would have shipped improvements that silently broke other parts of the system.
EXPLORE
Want to see the code?
The full source code, architecture documentation, and sample reports are available on GitHub.